[동아리] KHUDA 9기 : 방학 과제
created: 2026-01-17
last modified: 2026-02-16

파이썬 머신러닝 완벽 가이드
- 다양한 캐글 예제와 함께 기초 알고리즘부터 최신 기법까지 배우는 -
권철민
1. 머신러닝
머신러닝(Machine Learning)이란, 데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘 기법을 말한다.
- 데이터에 숨겨진 복잡한 패턴들을 스스로 찾아내고 신뢰도 있는 예측 결과를 만들어낼 수 있다.
- 데이터와 알고리즘 중에서는 데이터가 머신러닝 결과에 더 중요한 영향을 미친다.
머신러닝은 아래와 같이 분류할 수 있다.
graph LR
M["기계 학습<br>(Machine Learning)"]
S["지도 학습<br>(Supervised Learning)"]
N["비지도 학습<br>(Non-Supervies Learning)"]
R["강화 학습<br>(Reinforement Learning)"]
M --> S
M --> N
M --> R
S --> Regre["회귀 (Regression)"]
S --> Class["분류 (Classification)"]
N --> Clust["군집화 (Clustering)"]
N --> Dimen["차원 축소<br>(Dimentionality Reduction)"]
머신러닝을 할 수 있는 가장 대표적인 프로그래밍 언어는 python 이다.
python 머신러닝에 필요한 패키지들은 아래와 같다.
- 머신러닝 : Scikit-Learn
- 행렬/선형대수 : Numpy
- 데이터 처리 : Pandas
- 시각화 : Matplotlib / Seaborn
또한, 아래와 같은 소프트웨어를 사용할 수 있다.
- Jupyter Notebook
- Visual Studio
1주차
1장, 10장에서는 필수 Library들에 대해 알아본다.
1장 : 파이썬 기반의 머신러닝과 생태계이해
10장 : 시각화
2주차
2장 : 사이킷런으로 시작하는 머신러닝
2장에서는 sklearn의 dataset, preprocessing, model_selection에 대해 알아본다.
Machine Learning > Supervised Learning
Supervised Learning(지도 학습)은 정답이 주어진 데이터를 먼저 학습(train)한 뒤,
미지의 정답을 예측(prediction)하는 방식이다.
X(데이터: feature)→ y(정답: target)
이때, train 시 사용하는 데이터를 train data set,
prediction 시 사용하는 데이터를 test data set이라 한다.
대략적인 Superviesd Learning (Classification / Regression) 과정은 아래와 같다.
graph LR
data(["raw data"])
pre["Data Preprocessing"]
sel["Model Selection
&
Train/Predict"]
eva["Evaluation"]
model@{ shape: hex, label: "optimal model" }
data-->pre
pre-->sel
sel-->eva
eva-->model
6장 : 차원 축소
6장에서는 대표적인 차원 축소 알고리즘인 PCA, LDA, SVD, NMF에 대해 알아본다.
Machine Learning > Unsupervised Learning
Unsupervised Learning(비지도 학습)은 정답이 주어지지 않은 데이터를
① 다른 형태로 변환(차원 축소: X → X'(feature space의 차원을 축소) )하거나,
② 비슷한 데이터끼리 묶는(군집화: X → X1, X2, ...(feature space에서 가까운 것들을 묶는) ) 방식이다.
Machine Learning > Unsupervised Learning > Dimentionality Reduction
차원의 저주 (Curse of Dimentionality)
X(데이터)의 차원이 클 수록, 데이터 간의 거리는 기하급수적으로 증가하며, 필요한 데이터의 수도 기하급수적으로 증가한다.
따라서 X(데이터)의 차원을 축소(정보의 손실을 최소화한 채로)한다면, 상대적으로 데이터 수가 부족할 때에도 개선된 학습을 할 수 있다.
Dimentionality Reduction(차원 축소)는 Feature Selection(피처 선택)과 Feature Extraction(피처 추출)로 나눌 수 있다.
3주차
5장 : 회귀
5장에서는 회귀의 기본 개념과 회귀 모델들에 대해 알아본다.
Machine Learning > Supervised Learning > Regression
Regression(회귀)는 여러 $x_i$(feature)와 Continous한 $y$ (label)의 상관관계를 찾는 방법이다.
$y_i = f(x_{ij}, w_{ij})\quad where\:(data\:count\:\:i =1,2,\dots,n,\: features\:\:j =1,2,\dots,p)$ : 각각의 $x_i$가 어떻게 $y$에 영향을 미치는 지 $w_i$를 통해 설명한다.
행렬로는 $\boldsymbol{y}_{predicted} = f(X, W)$로 표현한다. ex) $\boldsymbol{y}=WX,\quad \boldsymbol{y}=X^{W_0}+W_1$
- W와 X가 선형 결합 / 비선형 결합 → Linear / non-Linear Regression
- X가 항이 1개 / 여러 개→ Simple Linear / Polynomial Regression (둘 다 Linear Regression이다)
좋은 모델 $f(X, W)$란, 주어진 학습 데이터 $X,\:\boldsymbol{y}$에 대해 목적함수$J(f) = Loss(\boldsymbol{y} , f(X, W)) + Regulation(W)$를 최소로 하는 최적의 weight $W'$로 구해진 모델 $f(X, W')$을 의미한다.
위의 목적함수 $J(f)$에서 정규항 $Regulation(W)$에 따라 이렇게 분류할 수 있다.
| $Regularization(W)$ | 이름 | 특징 |
| $\varnothing$ (없다) | Linear Regression | 가장 기본적. |
| $\lambda\|W\|$ $(l_1\:norm)$ | Lasso Regression | Feature Selection의 효과가 있다. |
| $\frac{\lambda}{2}\left\|W\right\|_2^2$ $(l_2\:norm)$ | Ridge Regression | 좀 더 강력한 Regularization 효과. |
| $\lambda_1\|W\|+\frac{\lambda_2}{2}\left\|W\right\|_2^2$ $(l_1+l_2\:norm)$ | ElasticNet | Lasso와 Ridge의 특징을 모두 가짐. |
Regularization이 필요한 이유는, 아래에서 알아볼 Overfitting(모델이 너무 복잡해지는 것)을 방지하기 위해서이다.
마찬가지로 위의 식에서 손실 함수 $Loss(\boldsymbol{y}, f(X, W))$ 는 이렇게 분류할 수 있다.
| $Loss(\boldsymbol{y}, f(X, W))$ | 이름 | 특징 |
| $\displaystyle\frac{1}{n}\sum_{i=1}^{n}|\:y_i-f(x_i,w_i)\:|$ | MAE (Mean Absolute Error) | Error를 선형적으로 반영. |
| $\displaystyle\frac{1}{n}\sum_{i=1}^{n}(\:y_i-f(x_i, w_i)\:)^2$ | MSE (Mean Squared Error) | 가장 기본적. 큰 Error를 더 크게(제곱) 반영 |
| $\displaystyle\frac{1}{n}\sum_{i=1}^{n}(\:y_i-(x_iw_1+w_0)\:)^2$ | RSS (Residual Sum of Square) | MSE에서 f(X, W)가 선형 모델일 때. |
| $\displaystyle\frac{1}{n}\sqrt{\sum_{i=1}^{n}(\:y_i-f(x_i, w_i)\:)^2}$ | RMSE (Root Mean Squared Error) | MSE의 증폭을 줄이기 위해 root를 씌움 |
| $\frac{predicted\:Variance}{real\:Variance}$ | R2 | 분산 기반으로 구함. 1에 가까울 수록 정확함. |
번외: Logistic Regression은 이름은 Regression이지만, 실제로는 Classification이다.
그렇다면 최적의 가중치 $W'$를 어떻게 구할 것인가?
수학적으로 생각해 보면, '연속인' 함수 $J(W)$는 $W=W'$일 때 '최솟값'을 가진다. (convex function)
따라서 $J(W)$를 미분했을 때, 그 값이 최소인($\nabla_W J(W) = 0$를 만족하는 $W$ 찾기) 지점을 찾는 문제라고 생각해 볼 수 있다.
| 수식 | 방법 | 특징 |
| (Loss: MSE, model f: Linear Regression)을 가정. $J(W)=||\boldsymbol{y}-W^{\top}X||_2^2$ $\nabla_W J(W) = X^{\top}XW-X^{\top}\boldsymbol {y} = 0$ $W' =(X^{\top}X)^{-1}X\boldsymbol {y}$ |
직접 미분하기 | W'의 정확한 값을 바로 구할 수 있다. 하지만 parameter 수=W의 크기가 아주 많아지게 되면, 수식의 계산 복잡도가 지나치게 복잡해져 특히 역행렬이 $O(n^3)$ 계산이 매우 힘들어진다. |
| W' = (랜덤 초기화) iterate: $W'_{new} = W'_{prev} - \tau \nabla_WJ(W'_{prev})$ $(\tau = learning\:rate)$ |
Gradient Descent (경사하강법) |
parameter 수가 아주 많을 때 유리하다. J(W)의 미분식만 구해 두고, 지속적으로 식을 반복하며 점진적으로 더 나은 해에 다가갈 수 있다. 더 변화가 없을 때까지 반복하지만, 그 결과가 최적의 해임은 보장되지 않는다. |
| 생략.. | 개선된 버전의 Gradient Desecent |
Gradient Descent에서 최적의 해를 보장하지 못하는local minima에 빠지는 문제를 일부 개선한다. (그래도 정확한 최적의 해를 찾음을 보장하지 못한다.) |
model이 너무 복잡해서 일반화 성능이 떨어지는 것(Train Data Set에만 맞춰짐)을 Overfitting(과대적합)이라 한다.
model이 너무 단순해서 추론 성능이 떨어지는 것(학습 자체가 덜 됨)을 Underfitting(과소적합)이라 한다.
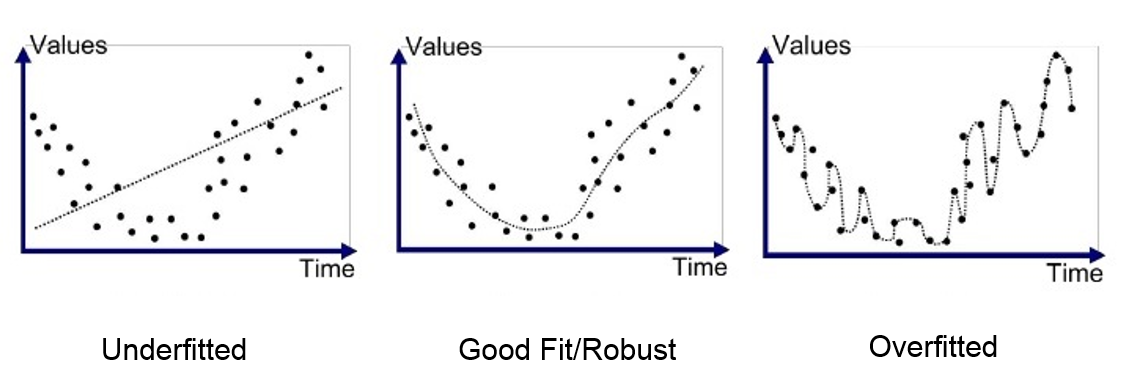
아래의 그림과 같이 Underfitting은 Bias가 높고, Overfitting은 Variance가 높다.


오른쪽의 그래프를 보면, model의 복잡도(크기)가 증가함에 따라 Error는 점차 감소하다가 다시 증가한다.
아래의 식을 보면, MSE는 실제로 Bias^2 + Variance임을 알 수 있다.
$\displaystyle \begin{gathered} Mean\:Squared\:Error\quad \frac{1}{n}\sum_{i=1}^{n}(\:y_i-f(x_i, w_i)\:)^2 \Rightarrow E[(y-\hat{y})^2], \\ Squared\:Error\quad S=(y-\hat{y})^2= (y-E[\hat{y}]+E[\hat{y}]-\hat{y})^2= (y-E[\hat{y}])^2+(E[\hat{y}]-\hat{y})^2+2(y-E[\hat{y}])(E[\hat{y}]-\hat{y})\end{gathered}$
$\displaystyle \begin{align} \therefore E[S]=E[(y-\hat{y})^2] &= E[(y-E[\hat{y}])^2]+E[(E[\hat{y}]-\hat{y})^2]+E[2(y-E[\hat{y}])(E[\hat{y}]-\hat{y})]\\ &=Bias[\hat{\theta}]^2 + Var[\hat{\theta}] + 0 \end{align}$
4주차
3장 : 평가
3장에서는 모델들을 평가하는 방법에 대해 알아본다.
4장 : 분류
4장에서는 분류의 기본 개념과 회귀 모델들에 대해 알아본다.
Machine Learning > Supervised Learning > Classification
Classification(분류)는 여러 $x_i$(feature)와 Discrete한 $y$ (label)의 상관관계를 찾는 방법이다.
기본 Classification model들은 아래와 같다.
| Logistic Regression | |
| Navie Bayes | |
| Decision Tree | Tree 기반 model들은 Regressor와 Classifier 모두로 쓸 수 있다. |
| Support Vector Machine | |
| Nearest Neighbors |
이외에도 Deep Neural Network
위의 기본 모델들을 활용한 Ensemble model들은 아래와 같다.
| Ensemble - Bagging | Random Forest |
| Ensemble - Boosting | AdaBoost |
| Ensemble - Boosting | Gradient Boosting |
| Ensemble - Boosting | ㅌgBoost |
| Ensemble - Boosting | LightGBM |
| Ensemble - Voting | Voting을 통해 여러 model의 prediction을 결합하는 기법 |
| Ensemble - Stacking | 여러 model의 prediction을 새로운 X로 하여 meta model로 최종 prediction을 구하는 방법. |
Decision Tree의 분류 기준(Impurity Criteria)는 크게 2가지가 있다.
| Gini Index | $\displaystyle 1 - \sum_{i \in y}{P_i}, \quad (P_i = \frac{\text{class i의 sample 수}}{\text{전체 sample 수}}) $ |
| Cross Entrophy | $\displaystyle - \sum_{i \in y} P_i \log{(P_i)} $ |
5주차
7장 : 군집화
7장에서는 대표적인 군집화 알고리즘인 K-Means, Mean Shift, Gaussian Mixture, DBSCAN에 대해 알아본다.
Machine Learning > Unsupervised Learning > Clustering
Clustering(군집화)란 label y 없이 X만으로 X의 cluster를 구하는 방법이다.
| K-Means | Hard EM algorithm | 임의로 cluster의 중심들을 잡는다. 1. 각 점을 가장 가까운 cluster에 할당한다. 2. cluster에 해당하는 점들의 평균으로 cluster의 중심을 갱신한다. (1과 2를 반복한다.) |
| Mean Shift | hyperparameter h(kernel 반경)을 정한다. 1. 각 점 $x_i$에 대해, 범위 h 안에 있는 이웃 점들을 찾는다. 2. 이웃 점들의 평균으로 $x_i$를 옮긴다. (1과 2를 반복한다.) |
|
| Gaussian Mixture | EM algorithm | 임의로 gaussian의 평균과 분산을 정한다. 1. 각 점을 가장 확률이 높은(가까운) gaussian에 할당한다. 2. cluster에 해당하는 점들로 gaussian의 평균과 분산을 갱신한다. (1과 2를 반복한다.) |
| DBSCAN | Density Based | hyperparamter eps(거리)와 min_nums(개수)를 정한다. 모든 점 $x_i$에 대해 eps 범위 내에 인접한 다른 점의 개수가 min_nums에 해당하는 점들을 고른다. 해당 점(Core Point)들을 연결하고, Core Point는 아니지만 Core Point와 인접한 점(Neighbor Point)을 포함하여 cluster를 만든다. 나머지 포함되지 못한 점들은 Noise Point로 취급한다. |
Clustering은 label이 없기 때문에, 명확한 정답이 없다.
하지만 Clustering을 evaluate하는 방식은 존재한다.
Silhouette Analysis
각 점 $x_i$에 대해, 아래와 같이 silhouette score를 구할 수 있다.
$x_i$와 동일한 cluster에 있는 모든 점 $x_j$에 대해,
$a(i) = mean(dist(x_i, x_j))$
$x_i$와 가장 가까운 cluster에 있는 모든 점 $x_k$에 대해,
$b(i) = mean(dist(x_i, x_k))$
$$\displaystyle silhouette\:score(i) = \frac{b(i)-a(i)}{max(a(i),b(i))}$$