created: 2026-03-10
last modified: 2026-03-17
- Machine Learning에 대한 배경지식이 있다고 가정한다.
- Deep Learning에 대해서는 이미 배운적이 있으므로,
cheating sheet 느낌으로 간단하게 정리한다.
1. Perceptron
Perceptron은 실제 뇌의 뉴런의 동작을 모방한 최초의 인공 신경망이다. 1957년에 나온 개념이다.
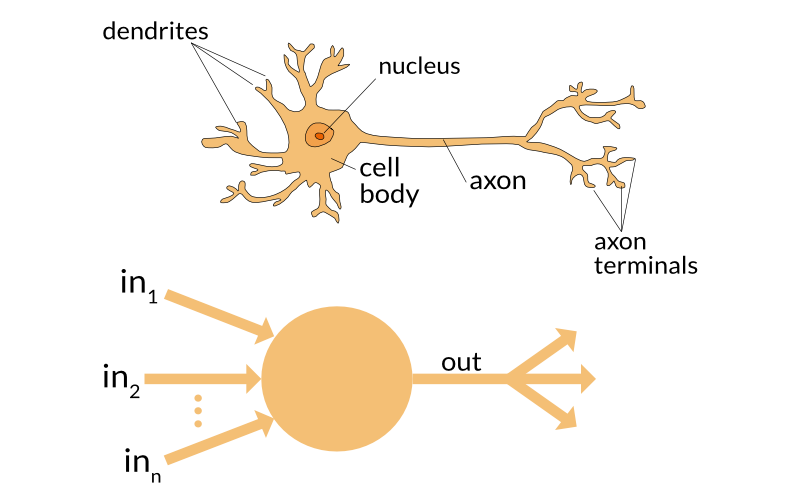
위의 그림은 뉴런의 구조이다.
자세한 구조는 알 필요 없고, 핵심 기능만 대강 알면 된다.
- 입력(dentrites): 다른 뉴런들로부터 신호를 받는다.
- (cell body / axon): 받은 신호를 모은다. 모은 신호를 뒤로 전달할 지 말지 결정한다.
- 출력(axon terminals): 처리된 신호를 다른 뉴런들로 신호를 전달한다.
위의 그림은 Perceptron을 나타낸 것이다.
왼쪽에서 봤던 뉴런의 핵심 기능을, 수학적으로 그대로 모사한다.
- 입력($x_1,x_2,..., x_n$) : output을 내기 위해 필요한 정보들이다.
- ( $\sum$ ): 각 $x_i$를, 가중치 $w_i$와 곱해서 모두 더한다.
- ( 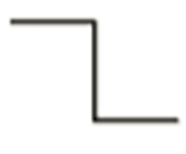 ): Step Function. 더한 결과가 양수면 1을, 음수면 0을 반환한다.
): Step Function. 더한 결과가 양수면 1을, 음수면 0을 반환한다.
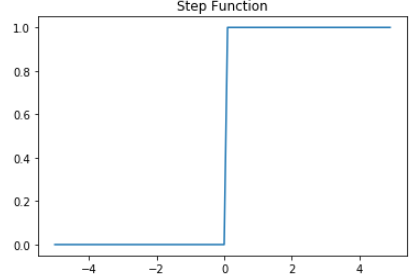
- 출력(y): 0 또는 1을 반환한다. (Binary Classification)
따라서 왼쪽 위 그림의 Perceptron은 아래와 같은 수식으로 나타낼 수 있다.
$\displaystyle \hat{y} = step(w_1x_1 + w_2x_2+...+w_nx_n)=step(\sum_{i=1}^n{w_ix_i}) = step(WX)$
이때 입력 $x_i$와 계수 $w_i$는 선형결합하고 있으므로, 기하학적으로 생각한다면 $WX$는 일종의 hyperplane(초평면)으로 해석할 수 있다.
학습이 완료된 가중치 벡터 $W$와 새로운 data $X_{new}$를 선형결합한 $WX$가,
step function에 의해 양수이면 class 1로 분류되고, 음수이면 class 0으로 분류되는 것이다.

1.1. Perceptron 학습은 어떻게 하는가?
'model을 학습한다'는 것은 data X를 가장 잘 설명하는 Weight를 찾는 것을 말한다.
Activation Function $A(X)$: Weight과 X의 선형결합 후, 왜곡을 부여하거나, 출력 범위에 맞게 바꿔주는 함수를 말한다. Perceptron에서는 step function에 해당한다.
model $f(X)$: 학습시키고 싶은 Weight를 가진 수학적 model을 말한다. 여기서는 Perceptron이다.
Loss Function $Loss(y, f(X))$: 실제 정답 $y$와 model의 예측값 $\hat{y}$ 간의 차이를 구한다.
Optimizer: Loss Function의 최솟값을 찾는 기법을 말한다. (Loss가 최소이다 = 실제 정답과 model의 예측값의 오차가 최소이다 = model의 예측력이 훌륭하다 = model이 훌륭하게 학습되었다.)
Perceptron의 학습법은 Machine Learning에서의 학습과 비슷하므로 생략한다.
1.2. Perceptron의 한계
Perceptron은 선형분류기이기 때문에 한계가 명확하다.
아래 그림과 같이, class 1과 class 0이 hyperplane 하나로 나눠지지 않으면, 분류할 수 없기 때문이다.

이를 해결하기 위해, hyperplane을 여러 개 사용하는 방법이 고안되었다.
아래 그림을 보면, 직선을 2개 사용함으로써, 새로운 feature space로 변환되었고, 새로운 feature space에서는 분류가 가능해졌다.

2. MLP
Multi-Layer Perceptron
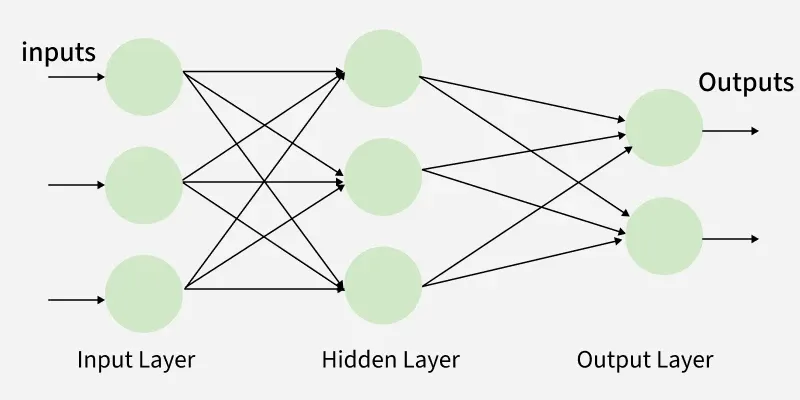
한 번에 여러 초평면을 기준으로 나누기 위해, 위에서 아래로 Perceptron을 쌓아 layer를 만들었다.
또한 이를 기준으로 더 분류하기 쉬운 feature space로 여러 번 변환하기 위해 해당 layer를 여러 번 쌓아 multi-layer Perceptron이 만들어졌다.
입력에 바로 맞닿아 있는 layer를 input layer,
출력과 바로 맞닿아 있는 layer를 output layer라 한다.
그 사이 드러나지 않는 layer를 hidden layer라 한다.
MLP에서 layer를 몇 층으로 할 건지, 각 layer에는 몇 개의 node(perceptron)을 둘 지는,
model을 학습시키기 전에 정해야 하는 일이다.
2.1 MLP의 한계
MLP에서는 Activation Function을 sigmoid를 썼었는데,
학습의 Back Propagation 시 sigmoid를 미분하는 과정에서, layer가 많으면, Loss function의 미분값이 0에 수렴하게 되는데,
이로 인해 학습이 잘 안되는 문제점이 있었다. (Vanishing Gradient)
추후에 ReLU 라는 Activation function이 등장하면서, layer의 수를 대폭 늘릴 수 있게 되었고,
이로 인해 layer가 '깊다'라는 의미로 Deep Neural Network, 즉 DNN의 시대가 열렸다.
3. DNN
Layer를 4층 이상 깊게 쌓은 Neural Network를 Deep Neural Network라고 한다.

이 그림은 5층을 쌓았다.
이렇게 층을 많이 쌓으려다 보니, 문제가 생기게 된다.
학습 시 Back Propagation 과정에서 앞 노드들로 gradient를 전달해야 하는데, 거리가 너무 멀어서 아래와 같은 문제들이 발생하곤 했다.
Gradient Vanishing 문제: (gradient에 계속 1보다 작은 값이 곱해지면서 0에 가까워져서, gradient가 update가 안됨)
(sigmoid에서 ReLU를 쓰니 구조적으로 개선되기는 했지만, 여전히 재수가 없으면 1보다 작은 gradient들이 곱해진다.)
Gradient Explosion 문제: (gradient에 계속 1부터 큰 값이 곱해지면서 너무 커져서, loss가 수렴이 잘 안됨)
같은 문제가 발생하게 된다.
특히 이는 가중치가 자유분방하게 되어 있는 학습 초기에 특히 많이 나타났으니, 가중치를 어떻게 초기화하는 것이 좋을지에 대한 논의가 대두된다.
| 모두 같은 값으로 초기화 | $w_i = 0$ | 학습불가. 모든 노드가 같은 방향으로 계산됨. -> 사실상 하나의 노드만 있는거랑 다를 바가 없어짐. |
| gaussian으로 초기화하기 평균 0, 분산 1 |
$w_i = gaussian(0, 1)$ | 학습불가. 학습을 시작하면 얼마 지나지 않아 0이나 1로 수렴해버림. |
| Xavier Initialization 분산을 $n_{in}, n_{out}$ 의 평균의 역수의 제곱근으로 |
$\displaystyle w_i = gaussian(0, \sqrt{\frac{2}{n_{in} + n_{out}}})$ | $n_{in}$은 $w_i$가 있는 layer의 입력 노드 수, $n_{out}$은 출력 노드 수. 나쁘진 않지만, 뭔가 ReLU랑 만나면 0으로 수렴하는 경우가 생긴다. |
| He Initialization 분산을 $n_{in}$만 고려함 |
$\displaystyle w_i = gaussian(0, \sqrt{\frac{2}{n_{in}})$ | ReLU를 써도 이제 weight가 고르게 분포하게 됨. |
또한 2017년 발표된 ResNet에서는 Residual Connection이라는 개념이 나왔다.
본래 node의 출력에, 그 node의 입력 X를 다시 더해줘서, 다음 노드로 넘기는 아이디어인데, 그 효과는 막강했다.
$\displaystyle \hat{y} = Activation(WX) + X$
본래 Vanishing Gradient 문제는 Activation의 미분값이 0에 근사해서 주로 생겼었는데, X를 더해주었더니, 기울기에서 0이 나오기가 힘들어졌다. Activation으로 sigmoid를 써도 layer 수를 많이 늘릴 수 있을 정도로 말이다.
1 epoch : 학습 과정에서 dataset 전체를 1 바퀴 학습한 것.
batch : 학습 과정에서 메모리 효율 / GPU 계산 효율을 높이고,
그리고 local minima에 빠질 확률 을 줄여주기 위해,
(dataset분포가 바뀜 → Loss Landspace 가 달라짐 → Local Minima가 미묘하게 달라짐)
한 번에 학습시키는 데이터를 bundle로 묶은 것.
iteration : 1 epoch를 돌기 위해 실행하는 횟수 (data 수 / Batch size)
Batch로 학습을 돌리다 보니, Internal Covariate Shift (내부 공변랑 시프트; 그냥 공변량 시프트라고도 한다.) 현상이 생겼다.
Internal Covariate Shift: batch 학습 중에 각 batch끼리의 데이터가 미묘하게 달라, layer가 진행될 수록 feature distribution이 점점 왜곡되는 현상을 말한다. 결국 심각하게 왜곡된 feature distribution은, 결국 0에 가깝거나(vanishing gradient) 폭발하는 (exploding gradient) 학습을 하게 된다.
원래 Covariate Shift문제란, train 데이터와 test 데이터가 미묘하게 달라, test dataset 추론 시에, 추론이 잘 안 되는 현상을 말한다.
이를 해결하기 위해, 모든 Batch가 동일한 distribution을 갖도록 만들어야 했다. 따라서 Batch 단위로 Normalization을 적용하는 Batch Normalization이 등장했다.
| Batch Normalization | for batch in batches: for column in features: $Normalize(x_i)$ |
가장 기본적인 Normalization. 실제로는 평균 0 / 분산 1로 만드는 것이 아니라, 임의의 평균과 분산을 알아서 찾아가게 만듦으로써, 최종 출력의 범위에 맞게 알아서 적당한 값을 찾도록 한다. |
| Layer Normalization | for sample in data: $Normalize(sample.features) |
Batch Normalization을 하고 싶은데,,, 데이터가 너무 적어서 Batch size가 너무 작을 때 사용. 그냥 sample 단위로 Normalize. Transformaer에서 많이 쓴다고 함. |
| Instance Normalization | for sample in data: for feature in sample: $Normalize(feature.channels)$ |
이미지 같은 곳에서는, 채널별로 Normalize를 하기도 한다. |
DNN이 나오고 나서도 수많은 연구가 있었고, 다양한 Activation Function, 다양한 기법 등이 개발되었다.
Perceptron의 선형 결합 대신에 convolution연산을 쓰는 CNN, graph 구조를 학습하는 GNN, 노드의 출력이 다음번의 입력에 포함되어 이전 상태를 기억하는 RNN 등 다양한 변종들이 존재하고,
DNN 자체를 보다 큰 모델의 일부로 87 transformer, mamba 등의 초대형 모델도 공개되었다.
이런 것들은 추후의 포스팅에서 알아볼 것이다.
이제는 DNN에서도 다양한 기법을 상황에 맞게 골라쓰는 시대가 되었다.
따라서 DNN에 쓰이는 간단한 기법들을 아래에 정리해 둔다.
Activation Function
다음 노드로 정보를 전달하기 전에
- hidden layer: 비선형적인 왜곡을 부여하거나,
- output layer: 출력의 형태를 원하는 범위로 변형해주는 역할.
| Step Function (계단 함수) |
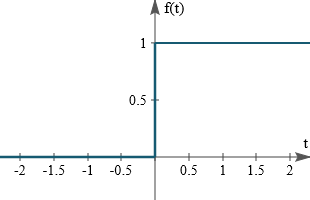 |
$\displaystyle \sigma(x) = \begin{cases} 1 & \text{if } x \ge 0 \\ 0 & \text{if } x < 0 \end{cases}$ |
거의 쓰이지 않는다. 항상 기울기가 0이므로 미분이 불가능하기에, Gradient Descent로 optimize할 수 없다. |
| Sigmoid | $\displaystyle \sigma(x) = \frac{1}{1 + e^{-x}}$ | 계단함수에서 기울기를 구할 수 있게 된 버전. hidden layer: 충분한 비선형적 왜곡을 부여하지만, layer가 깊어지면 gradient vanishing문제에 취약하다. 이를 해결하기 위해 Batch Normalization을 모든 hidden node의 출력에 적용할 수 있다. output layer: 0~1 사이의 출력을 낼 수 있다. |
|
| tanh | 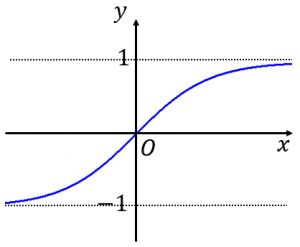 |
$\displaystyle \sigma(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$ | sigmoid와 거의 비슷하게 생겼지만, gradient vanishing이 조금 더 나은 버전. output layer: -1~1사이의 출력을 낼 수 있다. |
| ReLU (Rectified Linear Unit) |
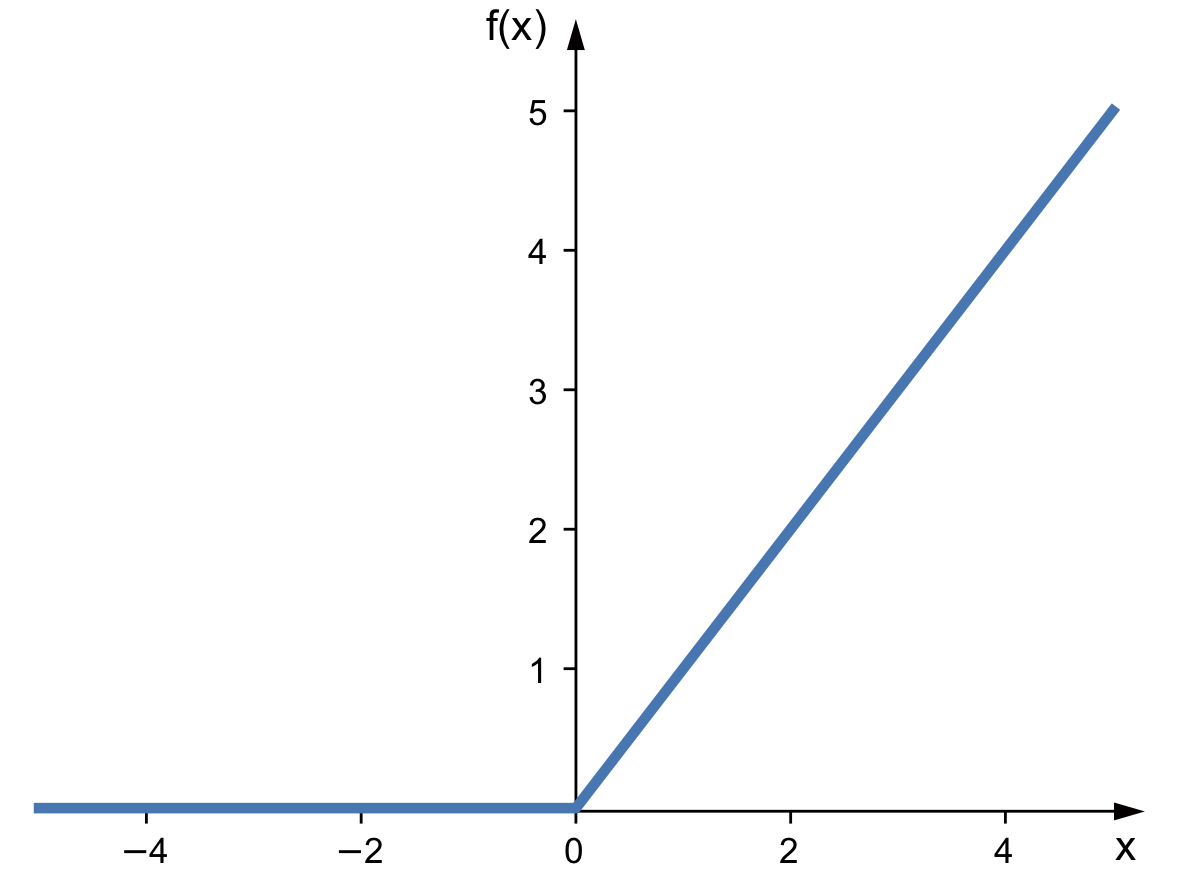 |
$\displaystyle \sigma(x) = max(0, x)$ | 간단한 형태에도 불구하고 gradient vanishing문제 없이 학습을 잘 시키는 걸로 화제가 되었던 함수. hidden layer: 에서 특히 많이 쓴다. |
| Leaky ReLU | $\displaystyle \sigma(x) = max(ax, x)$ | ReLU에서 음수 부분을 약간만 살려둔 버전. | |
| GeLU (Gaussian Error Linear Unit) |
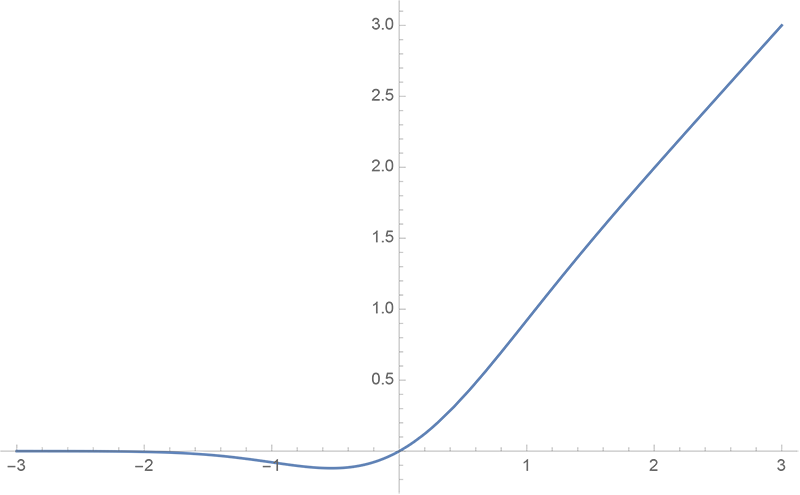 |
$\displaystyle \sigma(x) = x \cdot \Phi(x) \\ \tiny{\approx 0.5 \, x \left(1 + \tanh\Big[\sqrt{\frac{2}{\pi}}\left(x + 0.044715 x^3\right)\Big]\right)}$ | transformer FNN 구조에서 쓸 때 특히 성능이 좋은 버전. |
Loss Function
model의 예측값 $\hat{y}=f(X)$이 ground truth $y$와 차이가 크면 값이 크고, 비슷하면 작은 것을 목적으로 한다.
| MAE (Mean Absolute Error) |
$\displaystyle J(X;W) = \frac{1}{n} \sum_{i=1}^{n} \Big| y_i - f_W(x_i) \Big|$ | for Regression $y$와 $\hat{y}$ 를 뺀 값에 그냥 절댓값을 취한 것. |
| MSE (Mean Squared Error) |
$\displaystyle J(X;W) = \frac{1}{2n} \sum_{i=1}^{n} ( y_i - f_W(x_i))^2$ | for Regression $y$와 $\hat{y}$ 를 뺀 값을 제곱한 것. 차이가 크다면 MAE보다 더 크게 반영한다. |
| (Binary) Cross-Entrophy (Multinomial) Cross-Entrophy |
$\displaystyle \tiny{J(X;W) = - \frac{1}{n} \sum_{i=1}^{n} \Big[ y_i \log f_W(x_i) + (1 - y_i) \log (1 - f_W(x_i)) \Big]}$ $\displaystyle \tiny{J(X;W) = - \frac{1}{n} \sum_{i=1}^{n} \sum_{c=1}^{Classes} y_{ic} \log f_W(x_{ic})}$ |
for Classification $y$가 0이면 $-log(1-\hat{y})$이, 1이면 $-log(\hat{y})$가 적용된다. multinomial은 이 개념을 확장한 것이다. |
| (Binary) Focal Loss (Multinomial) Focal Loss |
$\displaystyle \tiny{J(X;W) = - \frac{1}{n} \sum_{i=1}^{n} \alpha \, (1 - f_W(x_i))^\gamma \, y_i \log f_W(x_i) + \alpha \, f_W(x_i)^\gamma \, (1 - y_i) \log (1 - f_W(x_i))}$ $\displaystyle \tiny{J(X;W) = - \frac{1}{n} \sum_{i=1}^{n} \sum_{c=1}^{Classes} \alpha_c \, (1 - f_W(x_{ic}))^\gamma \, y_{ic} \log f_W(x_{ic})}$ |
for Classification cross-entrophy의 개념에서, 특정 class에 더 집중할 수 있도록 강화되었다. |
| KL-Divergence | $\displaystyle D_{\text{KL}}(P \| Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)} $ | for 확률적 추정 확률분포 P와 Q 사이의 거리를 나타낸다. |
Optimizer
$Loss(y, y_{pred})$ 를 가능한 한 최소로 줄이는데 사용하는 기법
Learning Rate : 한 step에 Loss를 줄이는 방향으로 '얼마나 이동할 지'를 결정하는 비율.

Optimizer의 발전을 잘 설명하는 이미지.
출처
| Normal Equation (정규 방정식) |
$WX_{new} = y_{pred}$를 예측할 때, $W_{optimal} = (X^TX)^{-1}Xy$ |
요즘은 아무도 쓰지 않음. 장점: 반드시 Loss가 최소인 x를 찾아낼 수 있다. 단점: N이 커질수록 극도로 느려진다. 역행렬을 구하는 과정이 $O(N^3)$로 처참하기 때문. |
| Gradient Descent (경사하강법) |
$W_t = W_{t-1} - \alpha \nabla_W J(W_{t-1})$ | Loss함수의 기울기의 반대 방향(-)으로 이동함으로써 점진적으로 보다 나은 W를 찾아나가는 과정. |
| Stochastic Gradient Descent | 위와 같다. | Gradient Descent와 같으나, 하나의 data만 이용하여 $W_{k+1}$을 업데이트한다. 데이터의 수가 적을 때 사용한다. |
| mini-batch Gradient Descent | 위와 같다. | Gradient Descent와 같으나, batch 단위로 $W_t$을 업데이트한다. |
| Momentum (모멘텀) |
$\displaystyle \begin{align} v_t &= \beta v_{t-1} + (1-\beta) \nabla_W J(W_{t-1}) \\ W_t &= W_{t-1} - \alpha v_t \end{align}$ | gradient를 업데이트 하기 전에, 이전 시간 t-1 에 이동했던 방향 v(관성)방향을 약간 더해서 업데이트한다. |
| Nesterov Momentum (네스테로프 모멘텀) (NAG) |
$\begin{align}v_t &= \beta v_{t-1} + (1-\beta) \nabla_W J(W_{t-1} - \alpha \beta v_{t-1}) \\W_t &= W_{t-1} - \alpha v_t\end{align}$ | Momentum과 같으나, gradient를 한 step 더 나아간 위치에서 구한다. |
| Adagrad (Adaptive Gradient Descent) |
$\displaystyle \begin{align} g_{t-1} &= \nabla_W J(W_{t-1}) \\G_t &= G_{t-1} + g_{t-1} \odot g_{t-1} \\ W_t &= W_{t-1} - \frac{\alpha}{\sqrt{G_t + \epsilon}} \odot g_{t-1} \end{align}$ | ($\epsilon$은 분모가 0이 되지 않게 하는 아주 작은 값.) gradient $\nabla_W J(W_{t-1})$의 크기를 누적한 $G_t$를 분모로 보내서, Loss Landscape에서 gradient 방향 $w_i$ 가 너무 큰 방향은 줄이고, 너무 작은 방향은 키워서 안정적으로 학습시킨다. 하지만 $G_t$를 끝도 없이 누적하니 무한히 커지는 문제점이 있다. |
| RMSProp (Root Mean Square Propagation) |
$\displaystyle \begin{align} g_{t-1} &= \nabla_W J(W_{t-1}) \\G_t &= \beta G_{t-1} + (1-\beta)(g_{t-1} \odot g_{t-1}) \\ W_t &= W_{t-1} - \frac{\alpha}{\sqrt{G_t + \epsilon}} \odot g_{t-1} \end{align}$ | Adagrad의 문제점 ( ↑ )을 개선한 버전. β 를 곱해서 이전 $G_{t-1}$을 조금씩 잊겠다는 의도. |
| Adam (Adaptive Moment Estimation) |
$\begin{align} g_{t-1} &= \nabla_W J(W_{t-1}) \\ v_t &= \beta_1 m_{t-1} + (1-\beta_1) g_{t-1} \\ r_t &= \beta_2 v_{t-1} + (1-\beta_2) (g_{t-1} \odot g_{t-1}) \\ \hat{v}_t &= \frac{v_t}{1-\beta_1^t} \\ \hat{r}_t &= \frac{r_t}{1-\beta_2^t} \\ W_t &= W_{t-1} - \frac{\alpha}{\sqrt{\hat{r}_t} + \epsilon} \odot \hat{v}_t \end{align}$ |
Nesterov Momentum과 RMSProp를 결합한 버전. |
| AdamW | $\begin{align} g_{t-1} &= \nabla_W J(W_{t-1}) \\ v_t &= \beta_1 m_{t-1} + (1-\beta_1) g_{t-1} \\ r_t &= \beta_2 v_{t-1} + (1-\beta_2) (g_{t-1} \odot g_{t-1}) \\ \hat{v}_t &= \frac{v_t}{1-\beta_1^t} \\ \hat{r}_t &= \frac{r_t}{1-\beta_2^t} \\ W_t &= W_{t-1} - \alpha(\frac{1}{\sqrt{\hat{r}_t} + \epsilon} \odot \hat{v}_t + \lambda W_{t-1}) \end{align}$ |
Weight가 너무 복잡해지지 않도록(= overfitting되지 않도록), 맨 마지막 식에 Weight를 일부 줄여주는 Weight Decay를 추가했다. 준수한 성능을 보이며, Transformer의 optimizer로도 사용된다. |
Optimization 과정이 'Loss를 줄인다' → 'model이 dataset을 더 잘 나타낸다' → '더 학습되었다'.
'Domain Knowledge > Deep Learning' 카테고리의 다른 글
| [paper] mamba (0) | 2026.05.05 |
|---|---|
| [survey paper] GNN (2018/12) (1) | 2026.04.25 |
| CNN (1) | 2026.04.10 |