[실전기계학습] 수업 요약
created: 2026-04-10
last modified: 2026-04-10
- Machine Learning에 대한 배경지식이 있다고 가정한다.
- Deep Learning에 대해서는 이미 배운적이 있으므로,
cheating sheet 느낌으로 간단하게 정리한다.
1. Convolution Neural Network (CNN)
Convolution은 신호처리 이론에서 '주파수의 유사도' 를 검출하는데 쓰는 대표적인 기법이다.
주파수 형태로 된 데이터에는 이미지(Image), 동영상(Video), 음성(Audio), 전자기파(Radiowave) 등 다양한 종류가 있을 수 있다.
CNN을 설명할 때는 이 중에서 가장 흔하고 직관적인 Image를 통해 설명한다
Image는 아래의 특징들을 가지고 있다.
→ width x height 개의 pixel들로 구성되며, 일반적으로 하나의 pixel은 1개/3개의 channel을 가진다.
→ 각 pixel들은 모두 상/하/좌/우 의 격자 모양으로 인접하다.
→ 인접한 pixel일 수록 유사한 정보를 가진 pixel일 가능성이 높다. (이미지 속 사과 안의 한 픽셀을 고르면, 그 상하좌우 픽셀들도 사과일 가능성이 높다.)
따라서 Image에서 특정 객체를 검출하기 위해서는, 찾으려는 객체 형태의 kernel과 Convolution을 하는 방법이 최적이라고 생각할 수 있다.

Image와의 Convolution은 Computer Vision에서 더 자세히 알아볼 수 있다.
이 Convolution 연산의 kernel을, DNN의 개념에 적용하여 학습을 통해 최적의 kernel을 찾겠다는 것이 바로 CNN이다.
DNN의 perceptron node 대신에 convolution kernel을 학습시키는 것이다.
만약 kernel을 적용하지 않고, 모든 pixel 전부를 노드로 간주하여 DNN을 만들면, 엄청나게 많은 수의 weight가 필요할 것이다.
하지만 정해진 크기의 kernel을 convolution함으로써, 훨씬 적은 수의 weight를 가지게 하여 model의 크기를 획기적으로 줄일 수 있다.
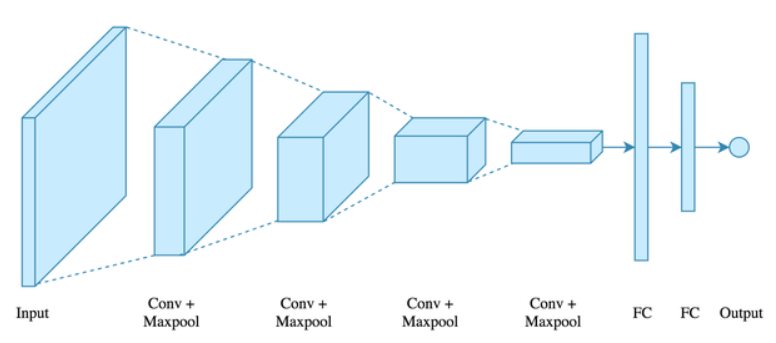
Convolution layer를 거칠 때마다,
원본 Input layer에서, width, height가 줄어들며 channel이 늘어나는 방식으로 정보를 변환한다.
이는 픽셀 방향으로 퍼져 있는 특징들을 점점 추출해 내는 과정으로 볼 수 있다.
위의 그림을 직접 더 자세하게 그려보면 아래와 같다.
Mnist dataset을 학습시킨 뒤, 추론하는 상황을 가정했다.

Convolution 아래의 kernel들은 전부 학습된 weight들이다.
위를 그리는데 사용된 pytorch model은 아래와 같다.
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
# Layers
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.fc = torch.nn.Linear(320, 10)
self.relu = torch.nn.ReLU()
def forward(self, X):
in_size = X.size(0)
X = self.relu(self.mp(self.conv1(X))) # 28x28x1 -> 24x24x10 -> 12x12x10
X = self.relu(self.mp(self.conv2(X))) # # -> 8x8x20 -> 4x4x20
X = X.view(in_size, -1) # 4x4x20 -> 320x1
X = self.fc(X) # 320x1 -> 10x1
return X
def visualize_weights(self):
weights = self.conv1.weight.detach().cpu()
fig, axs = plt.subplots(2, 5, figsize=(10, 5))
for i in range(10):
ax = axs[i//5, i%5]
ax.imshow(weights[i, 0], cmap='gray') # 10개의 5x5 필터를 그림
ax.axis('off')
plt.show()
def visualize_feature_map1(self, X):
with torch.no_grad():
feature_map = X.squeeze().cpu() # (10, 12, 12)
fig, axs = plt.subplots(2, 5, figsize=(8, 4))
for i in range(10):
ax = axs[i//5, i%5]
ax.imshow(feature_map[i], cmap='gray')
ax.axis('off')
plt.show()
def visualize_feature_map2(self, X):
with torch.no_grad():
feature_map = X.squeeze().cpu() # (10, 12, 12)
fig, axs = plt.subplots(4, 5, figsize=(4, 4))
for i in range(20):
ax = axs[i//5, i%5]
ax.imshow(feature_map[i], cmap='gray')
ax.axis('off')
plt.show()
시간이 없어 대충 넘어가는 것들
padding
stride
1x1 convolution - 무거운 연산 하기 직전에 channel방향 압축. 연산량을 크게 줄임.
residual connection - from resNet. 다른 ANN에도 무조건 쓰는 국룰 기법.
Inception module - from googleNet.
CNN 팁
사람들이 CNN을 사용해보며 Heuristic하게 알게 된 CNN 국룰이 있다고 한다.
1. CNN은 인접한 pixel들이 모여 하나의 정보가 된다. 다시 말해 정보 밀도가 높지 않다. 그래서 그런지 layer에서 차원을 증폭시키는 것이 별로 도움이 안 되는 것 같다.

2. CNN에서 사용하는 Fully Connected layer는 너무 deep하면 안 좋다. 최대 1~3 layer에, 정보압축을 크게 하는 것이 좋다. (위의 예시에서는 320차원을 10차원으로 단번에 줄였다.)
'Domain Knowledge > Deep Learning' 카테고리의 다른 글
| [paper] mamba (0) | 2026.05.05 |
|---|---|
| [survey paper] GNN (2018/12) (1) | 2026.04.25 |
| Perceptron부터 DNN까지 (0) | 2026.03.10 |